Abstract
The article introduces legislative Use Cases and the legal foundation for Semantic Compliance®. We import the text of US laws and regulations into the Financial Regulation Ontology (FinRegOnt). First, we take the less complex source, the Code of Federal Regulations (CFR), end-to-end, from extract to transformation and load into the ontology. Finally, we load the United States Code (USC).
Motivation
Financial Regulations are the Business Requirements for compliance. In conventional compliance efforts, Financial Institutions still map the requirements to implementing data structures and rules using MS Excel. Having the requirements and mapping within the ontologies facilitates concurrent maintenance, versioning, and end-to-end reporting.
Static Reference Data
The Federal Reserve Bank (FED) is the primary regulator for US Banks. The Securities & Exchange Commission (SEC) regulates Investment Funds. US Congress makes the law. We show how LKIF and FRO model these agents, their relationships, and their actions.
Semantic Data Integration
Semantic Data Integration is still Extract, Transform, as Figure 1 shows.
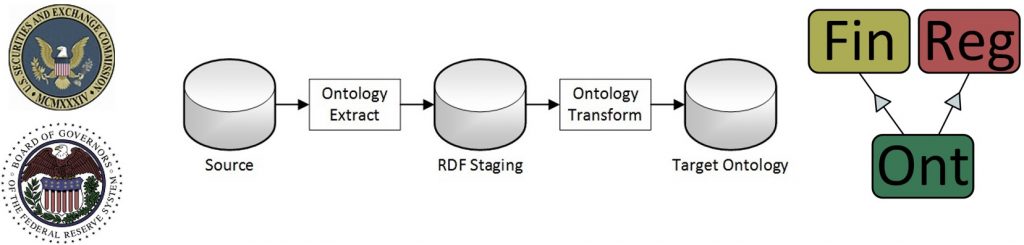
The article explains the conceptual, logical, and physical Data Integration model in a semantic environment. We use the TopBraid ontology tool set, but other ontology platforms and RDF data stores can substitute.
XML Sources
The Government Publishing Office (GPO) provides XML versions of the Code of Federal Regulations (CFR). FRO imports CFR Title 12 Banking and 17 Investment Adviser Act. The Office of the Law Revision Council (OLRC) codified the law and published it in XML format. FRO imports USC Title 12 and 15.
Ontology Model
This chapter dives deeper into Estrella LKIF modules Action and Medium. We explain where reference and XML source data instantiate classes and properties. FRO extensions to the reference ontology implement a Legal Document structure of defined classes and primitives for CFR and USC
FRO ties Legal Rules to the text of the law
The Ontology Knowledge layer makes the coding logic transparent to give Proof and Trust.
We want the law and regulations within the ontology and directly link them to their implementation. The diagram Figure 2 shows a Legal Rule, Investor Adviser Act Section §80b-2a 11, the SEC definition of Investment Advisers.

Semantic ETL and reverse engineering of Forms are not specific to investment funds. Any USC/CFR can be imported into the class structure. The example in this article and chapters 1 and 2 of the tutorial pertain to Funds and the SEC. But the ontology has USC/CFR Banks & Banking. Try out the steps with Title 12 Banks and Banking.
Legislative context of USC and CFR
The use case diagram in Figure 3 depicts the legislative processes and government actors that FRO is interested in.
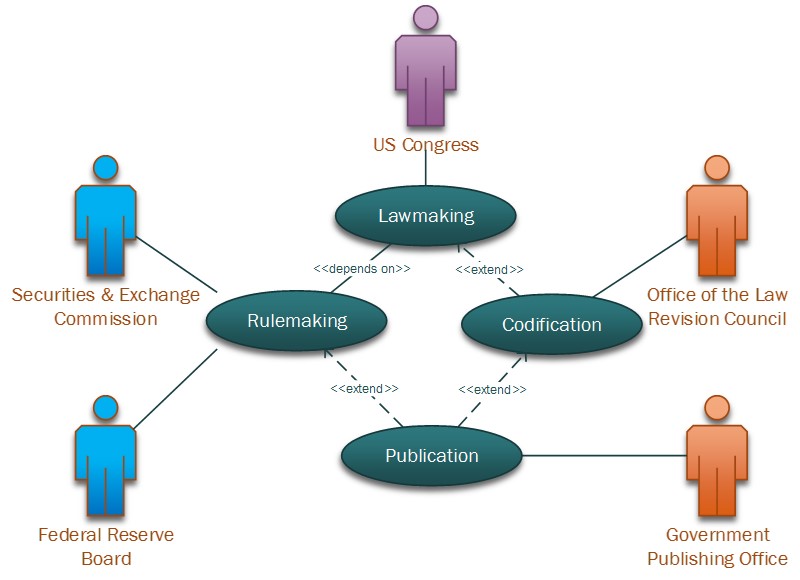
Codification and Publication produce the official version of laws and regulations.
- The US Congress enacts the Law. The original bills passed are input for Rulemaking and Codification. FRO doesn’t hold the bills but rather a revised and codified positive version.
- Office of the Law Revision Council codifies the law as an XML available for download.
- The financial regulators, SEC, FED, and others are authors of the Code of Federal Regulations.
- The Government Publishing Office makes the Code of Federal Regulations available in XML.
The tutorial chapter 2 explains in detail how FRO classes capture government actors and processes.
Data sources for laws and regulations
FRO sources XML for the United States Code from OLRC and the Code of Federal Regulations XML from GPO.
United States Congress enacted the Investor Adviser Act in 1940 to monitor and regulate the activities of Investment Advisers. The act placed mutual funds, closed-end funds, unit investment trusts, and exchange-traded funds under SEC regulation and supervision. The 2010 Dodd-Frank Act (DOF), Title IV required most Hedge and Private Equity Funds to register with the SEC.
The Office of the Law Revision Counsel (OLRC) of the US House of Representatives codifies and publishes the United States Code. As Positive Law the OLRC provides the latest version of the act including all changes and amendments. The OLRC website has the current laws available for download on their website.
FRO uses the OLRC XML Title 12 and 15 as a data source.
The Security and Exchange Commission implements the law. The SEC revises the Code of Federal Regulation with detailed instructions, forms, and procedures. The SEC hands over the new CFR to GPO for publication. The SEC supervises Investment Companies and Advisers. Note: For Banking the Federal Reserve is the main regulator. We cover the SEC in this tutorial, but the integration is the same.
The Government Publishing Office is the official source for Federal Government information. The “bulk” data is available in on the Federal Digital System (FDSys). The XML schema and a user guide are also published. FRO uses GPO XML files as a source for CFR.
CFR and USC in FinRegOnt ontology files
Financial Regulation Ontology instance files contain the text of laws & regulations relevant to Investment and Banking.
| United States Code | |||
| Title | Chapter | ||
| 12 | Banks and Banking | 17 | Bank Holding Companies |
| 53 | Wall Street Reform and Consumer Protection | ||
| 15 | Commerce and Trade | 275 | Investment Companies and Advisers |
https://finregont.com/fro/usc/
FRO_USC_Title_12_Chapter_17.ttl
FRO_USC_Title_12_Chapter_53.ttl
FRO_USC_Title_15_Chapter_2D.ttl
| Code of Federal Regulations | |||||
| Title | Chapter | Part | |||
| 12 | Banks and Banking | II | Federal Reserve System | 217 | Bank Holding Companies and Change in Bank Control (Regulation Y) |
| 225 | Bank Holding Companies and change in Bank Control (Regulation Y) | ||||
| 252 | Enhanced Prudential Standards | ||||
| 17 | Commodity and Securities Exchanges | II | Securities and Exchange Commission | 275 | Rules and Regulations, Investment Advisers Act of 1940 |
https://finregont.com/fro/cfr/
FRO_CFR_Title_12_Part_217.ttl
FRO_CFR_Title_12_Part_225.ttl
FRO_CFR_Title_12_Part_252.ttl
FRO_CFR_Title_17_Part_275.ttl
FRO Semantic Integration models
This section describes the architecture of moving Legal Sources into the Financial Regulation Ontology. The Data Integration process is similar to traditional Warehouses. We adopt Giordano’s integration modeling approach (Anthony David Giordano Data Integration Blueprint and Modeling, IBM Press 2011)
Figure 4 shows the High-Level Conceptual Semantic Integration Model. The “database” symbols stand for persistent storage in general, and the rectangles denote a process.
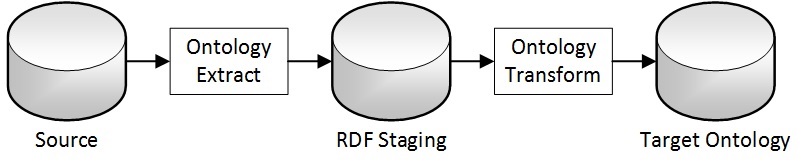
Data sources can have various formats: ontology files, XML, Spreadsheets, RDF Databases, or any data source with JDBC connectivity. We use TopBraid Maestro1 to import XML, but the Protégé and RDF Database environment also provide imports. RDF Staging and Target Ontology can be OWL files or graphs in an RDF Database. The Ontology Extract imports the Data Source and stores it in a “dumb” RDF Staging representation.
The Ontology Transformation operates completely in the Semantic environment. The transformation logic is encoded in SPARQL rules. We use TopBraid SPIN2, but Protégé and RDF Database environments also support SPARQL-based rules. RDF Staging is critical to the architecture and should not be bypassed. We do not want to encode business logic in the Extract process. We want uniform staging classes and utilize semantic transformation, no matter what the data source is.
Semantic Integration Logical Model
The logical integration model in Figure 5 shows a business rather than a technology view of the data integrations.
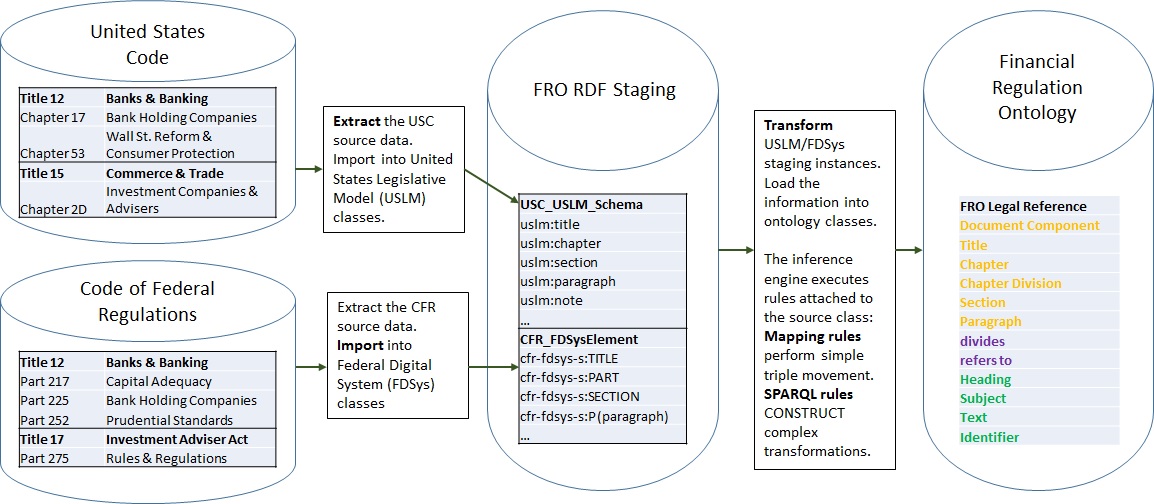
At the end, we want to access law and regulations in the Financial Regulation Ontology though:
- OWL classes: Document Component, Title, Chapter, Chapter Division, Section, and Paragraph
- OWL object properties divides and refers to connect the classes.
- OWL data properties hold text and numeric values such as Heading, Subject, Text, and Identifier.
From a logical perspective, we start out with the required CFR/USC Titles and Chapters, irrespective of their data sources and formats. There are two transformation steps from source to staging and then into target ontology:
1. Extract of the required laws and regulation from their source into an RDF/OWL representation.
- Extract the USC source data and import into United States Legislative Model (USLM) classes.
Populating USC USLM Schema classes: uslm:title, uslm:chapter, uslm:section, uslm:paragraph, uslm:note and others - Extract the CFR source data and import into Federal Digital System (FDSys) classes.
This populates the staging classes cfr-fdsys-s:TITLE, cfr-fdsys-s:PART, cfr-fdsys-s:SECTION, cfr-fdsys-s:P (paragraph)
2. Transform the staging instances into information for the FRO target classes
Transform USLM/FDSys staging instances and load the information into ontology classes. The inference engine executes rules attached to the source class. Mapping rules perform simple triple movement. SPARQL rules CONSTRUCT complex transformations.
Conclusion
We showed the reason for having the text of laws and regulations broken down into paragraphs and available within the ontology. The legislative context is static data with instances for regulators and government agencies. Laws and regulations are publicly available in machine-readable formats. We design a target ontology with the required granular level of paragraph. The Logical Semantic Integration Model identifies the source, staging, and target.
This model and approach are critical for Semantic Compliance.
There are different integration requirements, such as importing regulatory Forms or the Institution’s financial data.
They will come in various source formats: XML, XBRL, RDBMS, and proprietary flat flies.
But we will always put them into dumb staging first and then do an OWL to OWL semantic transformation. We do not want to encode business semantics in the source format-specific load process.
Details of CFR and USC import are in the Financial Regulation Ontology Tutorial Chapter 2, Loading the Law.